
| Nucleus Internet 101 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table of Contents
Web Browsers How to identify your web browser Often there is some confusion over what a web browser is and what type you are using. Many people don’t know what a web browser is or what it does. A web browser is a program used for viewing web pages over the internet. When you click on an icon on your desk top to view the internet, you are clicking on your web browser. There are many types of web browsers, the most common are Internet Explorer on the PC (this includes Dell, IBM, HP and Compaq among others), and Safari on the Macintosh (Including iMac, MacBook, iBook and Mac Pro). There are a number of other browsers that work on both Mac and PC as well both Internet Explorer and Safari are available for both Mac and PC. As you can see figuring out what browser you’re using can be quite confusing. Your first clue is the icon you’re clicking on to open it, the common ones are
When open on a PC you should see the icon representing each browser type in the top Right hand corner of the browser (unless it has been altered by a previous ISP. When open on a Mac the first menu at the top will be the name of the browser Identifying the version Now that we have a basic idea of what family of browser you are using you may need to troubleshoot an issue that is version specific. Also different options are available for user control in different versions of each browser so knowing what version of browser you are using can come in handy. To find the browser version: On a PC Click the Help Menu and chose ‘About Browser Name’ where Browser Name is the browser type you are using. For example when using Internet Explorer, chose Help > About Internet Explorer as seen below.
Note:If you are using Internet Explorer 8, the Help Menu may not be displayed by default. You will want to follow the same instructions as above, only click on the graphical help menu How to Enable the Menu Bar 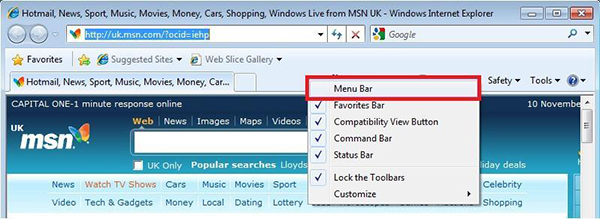
The After Effect As you can see, the Menu Bar is now displayed towards the top of the web browser as it is usually displayed in Internet Explorer 6 and 7. 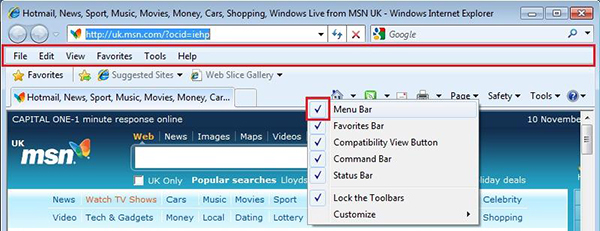
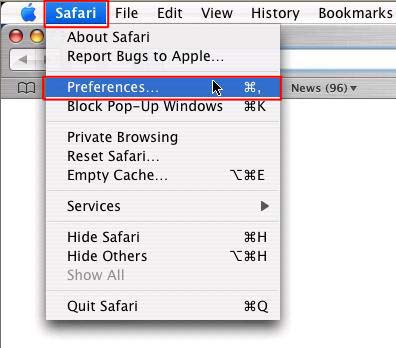
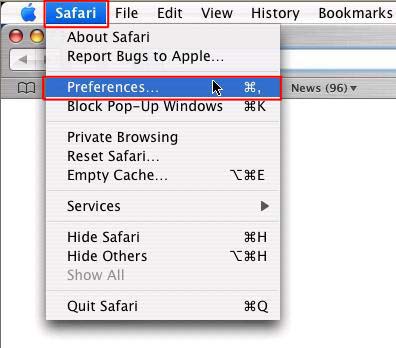
On a Mac Click the browser menu and chose ‘About Browser Name’ where Browser Name is the browser type you are using. For example when using Safari chose the ‘Safari’ menu and click ‘About Safari’ as seen below.
Using Web Browsers There are many common features available in most web browsers. Many newer browsers have functions for displaying Tabs (allowing you to have multiple pages open in a single window) as well all browsers have basic navigation features (Back, Forward, Home and Refresh). For a brief overview of the various functions available, please see the diagrams below. Internet Explorer 6
Internet Explorer 7
Internet Explorer 8
Safari
Bookmarks are a good way of keeping track of your most frequently visited websites. Most browsers, including all browsers named here have the option of saving bookmarks. IE 6 To create a favorite:
All favorites are saved under in the ‘Favorites’ menu IE 7 & 8 To create a favorite:
All favorites are saved under in the ‘Favorites’ menu or the new ‘Favorites’ button. Safari To create a bookmark:
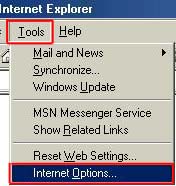
All Bookmarks are saved under the bookmarks menu. When you first open your web browser you usually go directly to a main homepage. In some cases this page is set by software you have installed, the computer manufacturer, or the browser developers. In most cases however the computer user (that’s you) will want to change the default homepage to one of their choosing. Usually it’s a good idea to set it to something you want visit often, or has information that updates daily or more frequently that you may want to see, that said it’s important to note you can set your homepage to ANY SITE ON THE INTERNET (not just one that it is pre-set to). Setting your default homepage is dependant on the type of browser you’re using. In Internet Explorer 6 Click ‘Tools’ and chose ‘Internet Options’
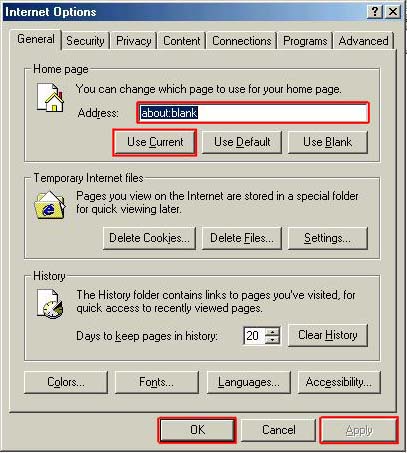
Then type the name of the homepage you want in the ‘Address’ line or alternatively if you are on the page you want as your home page click ‘Use Current’
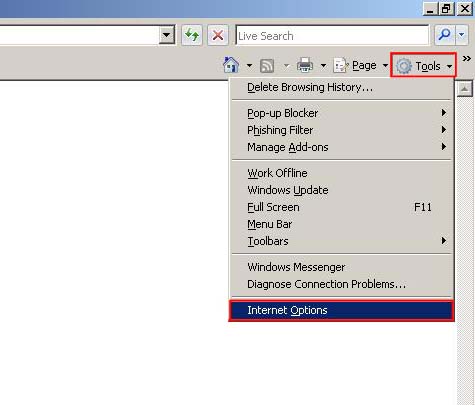
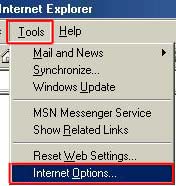
When you have the correct home page address in the ‘Address’ line, click ‘Apply’ then ‘OK’ In Internet Explorer 7 & 8 Click ‘Tools’ and chose ‘Internet Options’
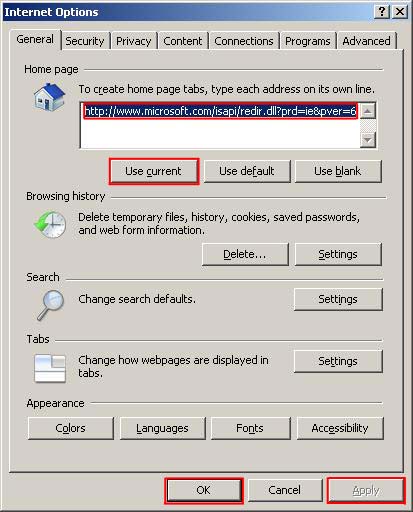
Then type the name of the homepage you want in the ‘Home Page’ Box or alternatively if you are on the page you want as your home page click ‘Use Current’
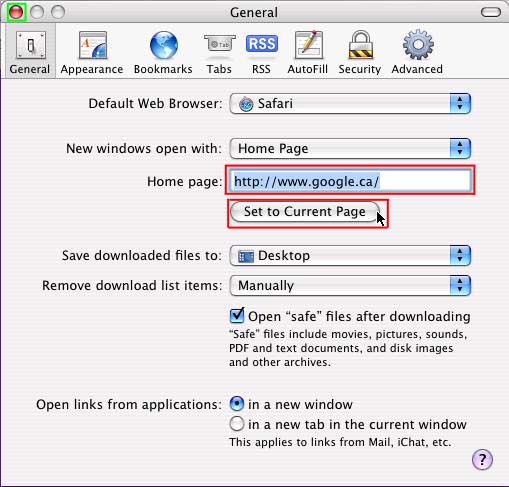
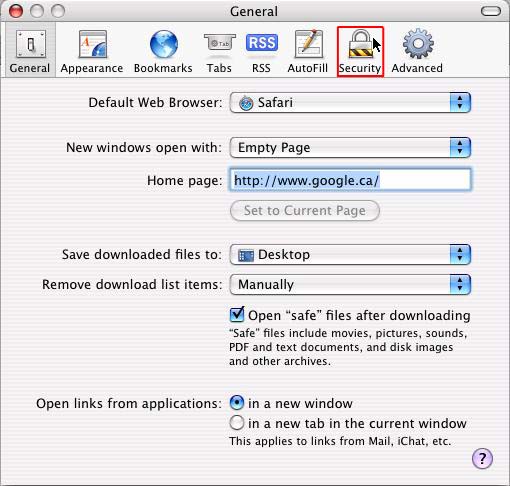
When you have the correct home page address in the ‘Home page’ box, click ‘Apply’ then ‘OK’ In Safari Click on the ‘Safari’ menu and click ‘Preferences’
Then type the name of the homepage you want in the ‘Home Page’ line or alternatively if you are on the page you want as your home page click ‘Set to Current Page’
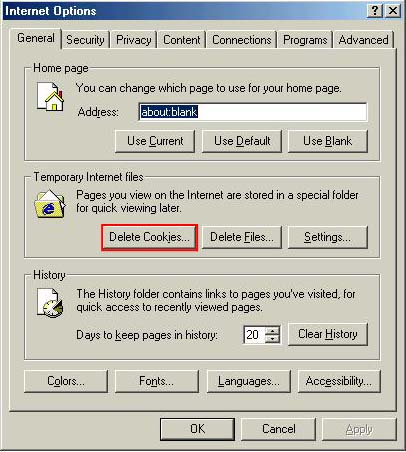
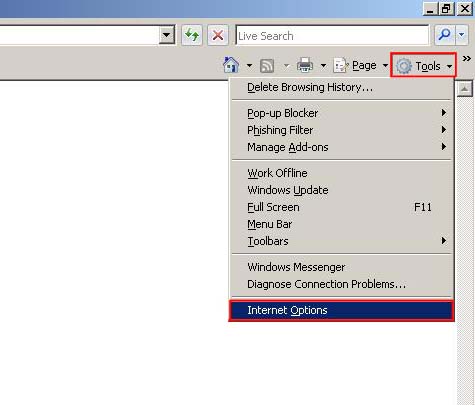
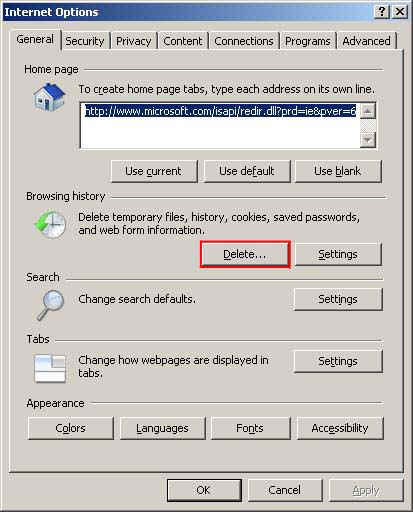
When the correct address is in the homepage line click the red button in the top left corner. Cookies, Java and Other Tasty Browsing Terms There is a lot of terms used on the internet and about the internet that can sometimes be quite confusing. Below there are some brief descriptions of what these terms mean and why you should know them. Cookies No not the chocolate chip kind. Cookies are pieces of information delivered from a Web site to the client's browser, and then stored on the hard drive. Examples are login or registration information, online “shopping cart” information, user preferences, etc. Cookies can be read by that web site on the next visit. The information stored in cookies can also be used to track browsing habits and retrieve personal information by spyware and malicious websites. Most cookies are fairly safe and some are automatically deleted when you log out of website. However there are some that are able to keep information for long periods of time and can be used to “automatically log in” to a website every time you go to it. While in some cases these can be restricted by the website to only be accessible by the original website, in some cases this information can be accessed by other websites and by spyware to hijack your online accounts or track the websites you commonly go to. Many security programs and clean up utilities have a feature to automatically delete cookies, you can also manually delete cookies in most browser programs. In Internet Explorer 6 Click ‘Tools’ and chose ‘Internet Options’ Then click the “Delete Cookies” button.
In Internet Explorer 7 & 8 Click ‘Tools’ and chose ‘Internet Options’
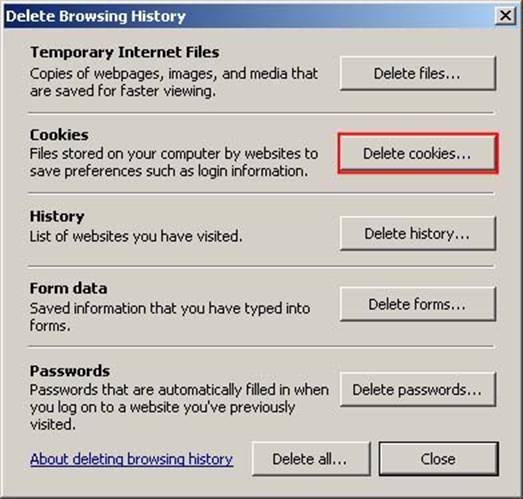
Click “Delete…”
In Internet Explorer 7 - click “Delete Cookies”
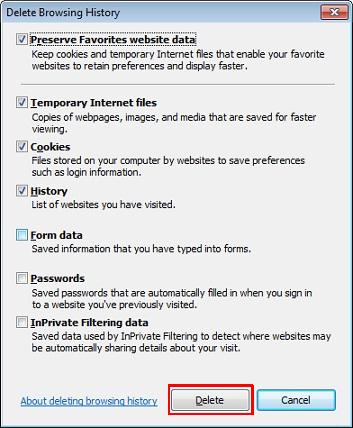
In Internet Explorer 8 - select what you would like to delete by checking the boxes on the left. Once this is done click “Delete ”
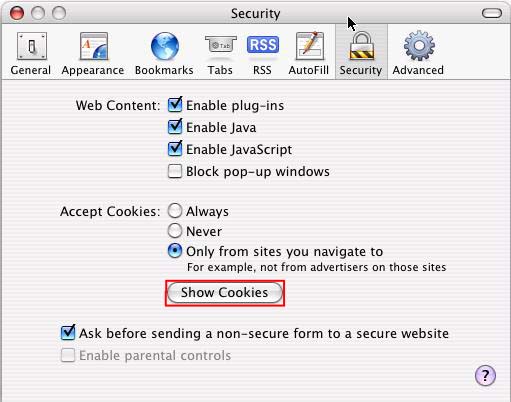
In Safari Click on the ‘Safari’ menu and click ‘Preferences’
Go to the ‘Security’ Tab
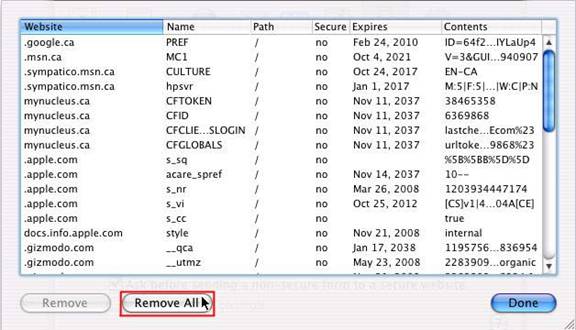
Click ‘Show Cookies’
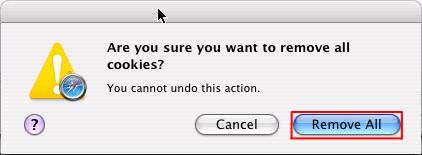
Click ‘Remove All’
And click ‘Remove All’ in the pop-up confirmation
Java, Flash, ASPX, Microsoft Silverlight, and Adobe Air These are specific types of programs and scripts run from within a browser that display content simple web page coding can’t. These are often used for online games, forums and chat rooms, and any number of other uses, they are essentially used programs made to run within programs (browsers) and can be used to make any kind of program you can run on your computer. The advantage of these kinds of programs is they are run, saved and accessible from the internet. You can access your information from any computer with an internet connection and don’t have to worry about them taking up space on your computer. The disadvantage of these kinds of programs is they are run, saved and accessible from the internet. Your information is being streamed across the internet and if not properly secured can be accessible to anyone with the time and motivation to find it. If your account on a web page is hijacked then the hijacker has unlimited access to all the information in your account, and you can only access it from online, so if you can’t access the internet you cannot access programs made with these tools. These program types typically involve installing an add-on, plug-in, or runtime on your computer so that your browser can read the programs. Any corruption in these add-on’s, plug-in’s or runtimes can cause tools and content written in these languages to fail to display. Java and Javascript Let us make a distinction here: Java is not Javascript, a common misconception created by two different organizations naming their products without consideration for the names of other products. Java is a programming language for writing full-blown software applications which are typically displayed through a web page, but are seperate, embedded components. Java programs but can also be run outside of the web browser, but those built into a webpage are referred to as Java Applets. Javascript is a scripting language commonly used for achieving visual effects and limited interactivity on a webpage, but is nevertheless part of the web page itself, not an embedded element Keeping your browser safe from infections and those who wish to steal personal information is often one of the most confusing of subjects when it comes to computers. The truth is there is no one right answer in terms of what you should be doing to keep your computer safe. Every person has an opinion on what you should do, but there is no 100% guaranteed method of securing your computer. The most anyone can do to protect them selves is make themselves a harder target than someone else. That said, there should be some things you should consider when deciding what kind of security works for you. An antivirus is the basic tool most people use to protect their computers. Antivirus are programs that scan information on your computer (and sometimes data coming in and going out as with mail scanning) for known viruses and things that look like known viruses. There are a number of different antivirus programs available ranging in price from free to $200.00+. The important fact to remember is that just about any antivirus will offer some level of protection, but in many cases having too big or intrusive an antivirus will affect computer performance and user experience. In many cases it may be necessary to disable certain features of an antivirus to use other programs on your computer as intended. A firewall is a program that blocks information coming in and out of a computer. Most firewalls will automatically “learn” what programs you normally use and what kinds of things they are allowed to do when you are using them. Other programs trying to get in to your computer from outside, or send information you don’t necessarily want sent (such as spyware) are usually blocked by a firewall. Please note a firewall will *Not* move, remove, or delete malicious software, it just stops it from sending out. In some cases a firewall will accidentally block a program you actually want to connect to the internet. In these cases it may be necessary to disable or manually change the firewall program. Anti-Spyware tools are programs that work much like anti-viruses. They scan your computer for spyware and adware that may have infected your computer. While the difference between a virus and spyware may be a bit vague, it is important to note that they *Are* different and while many antivirus programs now include a spyware scanner the reverse is not necessarily true (most anti-spyware programs are not virus scanners). *Note: pop-up blockers are not antivirus programs. They are something like firewalls for spyware in that they simply stop the pop-ups created by spyware, they don’t remove the infection. In addition, since many types of spyware don’t create pop-ups, it is usually preferable to use a true anti-spyware program than a pop-up blocker. In general the best software on earth isn’t going to protect you if you are browsing and using the internet in an unsafe manner. Your computer will never save you from actions you take of your own free will. As such here is a list of ways to protect your self when online:
Search Engines - Generation Technologies Summary The term "Search Engine" generically refers to publically accessible web sites that allow you to perform searches on the Internet for all kinds of content and information. Most people are familar with Search Engines such as the present-day Google or Yahoo! web sites. The first applications that performed internet searching tasks were not found on web sites, but were instead programs that ran locally on your computer. Examples were Archie and Gopher and were used prior to 1993. The technology of Search Engines is still evolving and there are many companies world-wide offering products to improve "data mining". Generally speaking, the ultimate goal in this field for computers to accurately produce personalized search results when queried in a way that's intuitive to humans. Presently, there are many mathematically and syntactically formalized approaches for searching large bodies of data as well as specialized systems for searching through specific types of data, such as audio files. For the average person, using such facilities is unwieldy and presents a large learning curve which makes them unsuitable as public search products. Ideally, rather than using mathematical and "machine" language queries to find information, we would instead prefer to have a system that lets us ask it questions, as if we were speaking to another person who has an "intuitive sense" of the context question as well as the relevancy of the answers we're looking for. Such a text is highly human-oriented and very difficult to instruct a machine to do. Presently there is no solution for this, but there are many proposed technologies that will bring us closer to it.
Searching the Web The process of actually searching the Web for material that interests you is very simple and straight forward. You're able to search the entire Web, specific Web Sites, news articles, pictures and more from a single web site (the search engine). Having such a page bookmarked in your Web Browser, or even setting it to your Home Page is a typical, easy method for users to go to the search engine when they need it. Below, we've provided a list of several Web Pages on the Internet that are search engines, sorted alphabetically. Just click a link to explore the engine! In each case the idea is always the same - simply type words or a question related to your interests into the search field on the page and click the Search button.
Once niche application for search engines is in the location of specific people (or information about them). Typical resources might simply be online Phone Books, but there are other online search engines that are capable of revealing incredibly detailed data about searched people. Here are a few examples of these engines:
Searching for Places
Finally, another novel variety of searchable content on the web are geographic maps - simply typing in a complete address is usually enough for these types of engines to pinpoint the location on either a drawn map, a satellite map or both (a hybrid map). In addition to location services, the engines are usually also capable of providing optimized travel instructions between two addresses. Have a look at the following links:
Search Technology - Advanced Details Most people won't be too interested by the details presented about Search Engines on the remainder of this page as it's a bit more technical and certainly not required information. If you don't really care about how a search engine finds stuff for you, then you can just skip the content that follows... If, on the other hand, you're still curious about how Search Engines work and where they're headed for the future, then you should check out what we've included below. To start with, we've made a brief summary of the various "generations" of technologies that have been used for searching internet content since the early 1990's. First and Second Generation Search engines are now things of the past, while ideas about a Fourth Generation are only just beginning to appear. As of this writing (early 2008), we're at the border between 2nd and 3rd generation search engines...
Search Engines - Gen 2 Technologies To follow up the previous section, let's take a closer look at how search engines actually work by breaking down their various mechanisms into identifiable pieces and then describing each. Keep in mind that the technology behind search engines is private - proprietary solutions developed in-house by the companies that host the search services. Having said that, one can really only guess at how their products actually produce results. Nevertheless, a lot about search engine operation is known, even though the software that runs them is secret. Search engines have three states of operation: 1. Web crawling (Spidering) - at this stage, automated web browsers follow every link they encounter, set in motion from a "core" group of web pages supplied to them by human operators. Page contents are subsequently analyzed using a variety of methods (see below), the results of which are then stored in a large, organized database. 2. Indexing - having harvested a web page for information and analyzed those contents in step 1, those results are now stored in a database which will later be referenced to answer search queries from an end-user. To avoid redundant work, pages already indexed are obviously not Spidered again. An index has a single purpose: It allows information to be found as quickly as possible. There are quite a few ways for an index to be built, but one of the most effective ways is to build what's called a hash table. In hashing, a mathematical formula is applied to attach a numeric value to each word that will be entered into the database. The formula is designed to evenly distribute the entries across a predetermined number of divisions and it is this numerical distribution, which is different from the distribution of words across the alphabet, that is the key to a hash table's effectiveness - a given word will always "hash" to a specific spot in the database, which can almost instantly return matched results. 3. The Search Facility - this is the user interface and software engine (a web page like Google or a locally-run application) that provides a syntax (or some other means) for a user to retrieve tailored results from the indexed database content once they submit a search query. At the first appearance of 2nd-generation search engines, the techniques used to produce results had evolved from simple keyword lookups to involve the following major components which helped to adjust the relevancy of search results, allowing engines to order (or even exclude) matched pages with poor ratings:
Advances in Gen 2 Engine Technology Following the introduction of 2nd Generation search engines, their authors began to introduce a variety of new systems to improve the accuracy of search results. Here's a summary of the techniques that have been employed to date:
Search Engines - Gen 3 Technologies
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




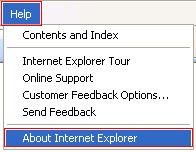
 and then proceed to click on About Internet Explorer. If you would like to display the Menu Bar (contains File, Edit, Favorites, Help etc) simply right click by the graphical buttons at the top and enable Menu Bar (see below for more details on how this is done).
and then proceed to click on About Internet Explorer. If you would like to display the Menu Bar (contains File, Edit, Favorites, Help etc) simply right click by the graphical buttons at the top and enable Menu Bar (see below for more details on how this is done).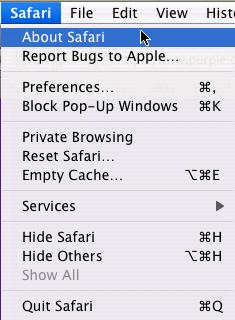
|
|||||||||||||||||||||||||||||||||||||||||||||||||